9 Functionals
9.1 Introduction
코드가 더 믿을만하려면, 더 투명해야 한다.
특히나, nested conditions랑 루프는 의심을 갖고 보아야 한다.
복잡한 control flows는 프로그래머를 혼란스럽게 한다.
복잡한 코드는 종종 버그를 숨기고 있다.
To become significantly more reliable, code must become more transparent.
In particular, nested conditions and loops must be viewed with great suspicion.
Complicated control flows confuse programmers.
Messy code often hides bugs.
자 그래서 functional 무엇이냐? function과는 어떻게 다른 것인가?
functional은, input을 함수로 받고, output을 벡터로 return하는 함수.
A functional is a function / that takes a function as an input / and returns a vector as output.
간단한 Functional을 소개해보자.
1000개의 random uniform numbers를 input으로 넣은 함수를 호출call하는 functional.
randomise <- function(f) f(runif(1e3))
randomise(mean)
## [1] 0.4814433
randomise(mean)
## [1] 0.4926265
randomise(sum)
## [1] 494.4899
이미 functional을 사용해봤을 수 있다.
for 루프문을 대신하기 위해 base R의 lapply(), apply(), tapply() 혹은 purrr의 map()을 써봤을거다.
혹은 수학적 functional인 integrate()나 optim()을 써봤을 수도 있다.
functional을 주 용도는 for 루프를 대신해서 쓰는 것이다.
for 루프는 많은 사람들이 느리다고 믿기 때문에, R에서 평판이 안 좋다.
하지만 for 루프의 진정한 단점은 for 루프가 너무 유연하다는 것이다.
루프를 사용하면, 반복한다는 의도를 전달할 수 있지만, 그 결과물로 무엇을 해야하는지는 알려주지 않는다.
a loop conveys that you’re iterating, but not what should be done with the results.
repeat 대신에 while이, while 대신에는 for을 사용하는 것이 낫듯이,(Section 5.3.2)
for대신에 functional을 사용하는 것이 낫다.
각 functional은 특정한 작업에 잘 맞추어져있기 때문에, functional을 보면 왜 쓰는지를 바로 볼 수 있다.
Section 5.3.2 내용
어떠한for 루프도 while로 쓸 수 있고, 어떠한 while도 repeat을 이용해서 쓸 수 있고. 하지만 역은 성립하지 않는다.
이 말은,
while은 for보다 flexible하고, repeat은 while보다 flexible하다는 것. 하지만, 가장 flexible하지 않은 것을 이용하는 것이 좋은 습관이기 때문에, 가능하면
for문을 써야 한다. 그리고 더 일반적으로는, for문을 이용할 필요가 없다.
왜냐하면 map()이랑 apply()가 대부분의 문제들에 있어, 이미 less flexible한 솔루션을 제공하기 때문.
그래서 만약에 니가 loop에 익숙한 유저라면, functionals로 스위칭하는 것은 그냥 패턴 매칭 연습하는 것에 지나지 않는다.
for 루프를 보고, 알맞은 기본형 functional을 매치시키면 된다.
만약에 그런 것이 존재하지 않는다면, 이미 존재하는 functional을 변형해서 찾으려고 노력하지 마라.
그냥 for 루프로 남겨둬라!(하지만, 만약에 같은 루프를 두 번 이상 반복해야 한다면, 자신의 functional을 쓸 생각도 해봐야 한다.)
Prerequisites
이 chapter에서는, purrr package에 있는 functional에 집중할 것이다.
일관적인 인터페이스를 갖고 있어서, base에 있는 것들보다 핵심 아이디어를 더 이해하기 쉽다.
몇 년에 걸쳐 유기적organically으로 개발된 것이다.
base R의 동일한 것들equivalents과, 앞으로도 비교대조하겠다.
그리고 purrr에는 없는 base functionals에 대한 논의discussion로 chapter 마무리를 하겠다.
library(purrr)
9.2 My first functional: map()
가장 기초적인 functional은 purrr::map()이다.
①a vector와 ②a function을 받고, 벡터의 각 element에 대해 함수를 호출한다.
그리고나서 결과물을 리스트로 return한다.
즉, map(1:3, f)는 list(f(1), f(2), f(3))과 같은 것이다.
triple <- function(x) x * 3
map(1:3, triple)
## [[1]]
## [1] 3
##
## [[2]]
## [1] 6
##
## [[3]]
## [1] 9
시각적으로 나타내면, 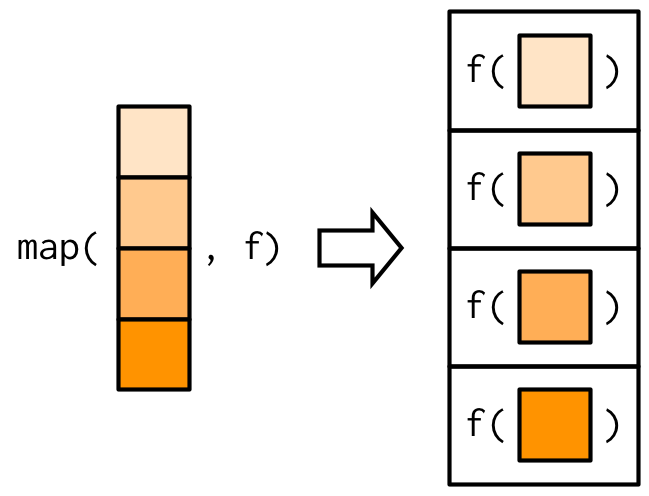
왜 이 함수를 map()이라고 할까?
지도가 아니라 수학적인 map, "given set의 각 element를, 두 번째 set의 하나 혹은 이상의 elements로 association시키는 연산operation"이라는 뜻에서 map()이라고 부르는 것이다.
(그리고 "Map"이라는 단어는 스펠링이 짧아서 기초적인 building block이 되기에 좋다.)
map()의 implementation은 꽤나 간단하다.
input과 같은 길이의 리스트를 만들어놓고, 리스트의 각각을 for 루프를 사용해서 채운다.
implementation의 핵심은 코드 몇 줄 되지 않는다.
simple_map <- function(x, f, ...) {
out <- vector("list", length(x))
for (i in seq_along(x)) {
out[[i]] <- f(x[[i]], ...)
}
out
}
실제 purrr::map()은 이렇게 만들어지진 않았다. 몇 가지 차이점이 있다.
C언어로 써서 성능을 조금이라도 더 짜냈고, 이름을 보존하고, Section 9.2.2에서 배울 몇 가지 shorcuts들을 지원한다.
base R에서는
map()과 동등한 base 함수는 lapply()다.
유일한 차이는 lapply()는 밑에서 배우게 될 helpers를 지원하지 않는다는 것이다.
그래서 만약에 purrr에서 map()만 쓸 것이라면, 추가적인 의존성additional dependency를 스킵하고 lapply()를 쓰면 된다.
9.2.1 Producing atomic vectors
map()은 리스트를 return하는데, map family가 가장 일반적일 수 있게 해주는 거다.
왜냐하면 그 어떤 것이라도 리스트에 넣을 수 있기 때문.
그런데 더 간단한 데이터 구조data structure가 가능한데, 꼭 리스트를 return하게 하는 것은 불편.
그렇기 때문에 4가지의 더 특정한 변형들이 있다. map_lgl(), map_int(), map_dbl(), map_chr()
각각은 특정화된specified 타입의 벡터를 return해준다.
. map_chr()은 항상 character vector를 return한다.
map_chr(mtcars, typeof)
## mpg cyl disp hp drat wt qsec vs
## "double" "double" "double" "double" "double" "double" "double" "double"
## am gear carb
## "double" "double" "double"
. map_lgl()은 항상 logical vector를 return한다.
map_lgl(mtcars, is.double)
## mpg cyl disp hp drat wt qsec vs am gear carb
## TRUE TRUE TRUE TRUE TRUE TRUE TRUE TRUE TRUE TRUE TRUE
. map_int()은 항상 integer vector를 return한다.
n_unique <- function(x) length(unique(x))
map_int(mtcars, n_unique)
## mpg cyl disp hp drat wt qsec vs am gear carb
## 25 3 27 22 22 29 30 2 2 3 6
. map_dbl()은 항상 double vector를 return한다.
map_dbl(mtcars, mean)
## mpg cyl disp hp drat wt
## 20.090625 6.187500 230.721875 146.687500 3.596563 3.217250
## qsec vs am gear carb
## 17.848750 0.437500 0.406250 3.687500 2.812500
purrr은, 접미사suffix만 봐도 output이 무엇이 될지를 알 수 있도록 했다.
_dbl이면 double vector가 output이겠구나! 하게끔.
모든 map_*()함수들은, 어떠한 타입의 벡터든 input으로 받을 수 있다.
mtcars는 데이터 프레임이고, 데이터 프레임은 같은 길이의 벡터들을 갖고 있는 리스트들이다.
data frames are lists containing vectors of the same length.
벡터 때와 마찬가지로 그림으로 그려서 표현해보면, 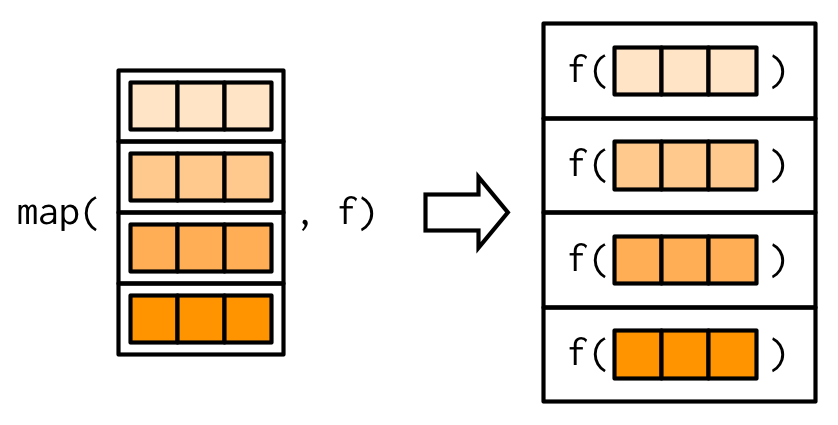
모든 map 함수들은 input과 같은 길이를 갖는 output 벡터를 return해야한다.
length(mtcars)
## [1] 11
length(map_dbl(mtcars, mean))
## [1] 11
이 말인즉슨, .f의 각 호출call이 single value를 return해야한다는 것이다.
만약 그렇지 않다면, 에러가 나온다.
pair <- function(x) c(x, x)
map_dbl(1:2, pair)
## Error: Result 1 is not a length 1 atomic vector
이 때의 에러는, .f가 잘못된 타입일 때 얻게되는 에러와 같다.
map_dbl(1:2, as.character)
## Error: Can't coerce element 1 from a character to a double
위 2가지의 경우에 있어, 그냥 map()을 쓰는게 낫다.
왜냐하면 map()은 어떠한 타입의 output이든 다 받아주기 때문이다.
이러고나면 output이 어떻게 생겼는지를 알 수 있고, 뭘 해야할지를 알게 된다.
map(1:2, pair)
## [[1]]
## [1] 1 1
##
## [[2]]
## [1] 2 2
map(1:2, as.character)
## [[1]]
## [1] "1"
##
## [[2]]
## [1] "2"
base R에서는
base R은 atomic vector를 return하는 2개의 apply 함수들을 가지고 있다.
sapply()랑 vapply()
sapply()는 비추하는데, 왜냐하면 얘는 results를 간단화simplify시키려고 노력을 하기 때문에,
list를 return할 수도, vector를 return할 수도, matrix를 return할 수도 있기 때문이다.
이러면 프로그램을 하기가 힘들어지고, non-interactive 셋팅에서는 피해야할 일이다.
vapply()는 FUN.VALUE라는 template를 제공해서, output shape를 describe해주기 때문에 더 안전하긴 하다.
만약 purrr을 이용하고 싶지 않다면, sapply()가 아닌, vapply()를 항상 이용하기를 권한다.
vapply()의 단점으로는, 너무 장황verbosity하다는 것이다.
예를 들어, map\_dbl(x, mean, na.rm = TRUE)를 base R로 써보려고 하면,
vapply(x, mean, na.rm = TRUE, FUN.VALUE = double(1))이다.
9.2.2 Anonymous functions and shortcuts
이미 존재하는 함수와 map()을 쓰는 것 대신에, inline anonymous 함수를 쓸 수도 있다.(Section 6.2.3)
(anonymous 함수라는게 대단한 것은 아니고, 이름도 붙일 필요 없는 그냥 한 줄짜리 간단한 함수.)
map_dbl(mtcars, function(x) length(unique(x)))
## mpg cyl disp hp drat wt qsec vs am gear carb
## 25 3 27 22 22 29 30 2 2 3 6
anonymous 함수는 굉장히 유용하지만, 문법syntax이 좀 길다. 그래서 purrr은 shortcut을 제공한다.
map_dbl(mtcars, ~ length(unique(.x)))
## mpg cyl disp hp drat wt qsec vs am gear carb
## 25 3 27 22 22 29 30 2 2 3 6
모든 함수들이 ~(twiddle이라고 발음함)로 시작하는 formula를 함수function로 번역해주기 때문에, 이게 가능하다.
as_mapper()를 사용해서 무엇이 일어나고 있는지를 확인할 수 있다.
as_mapper(~ length(unique(.x)))
## <lambda>
## function (..., .x = ..1, .y = ..2, . = ..1)
## length(unique(.x))
## attr(,"class")
## [1] "rlang_lambda_function" "function"
이 함수 argument는 유별나보이지만quirky,
하나의 argument를 갖고 있는 함수에 대해서는 .를 통해서 refer을,
두개의 arguments를 갖고 있는 함수에 대해서는 .x와 .y를 통해서 refer을,
그 이상의 arguments를 갖고 있는 함수에 대해서는 ..1, ..2, ..3 등등을 통해 refer을 할 수 있도록 해준다.
.는 하위 호환성backward compatibility를 위해서 남겨두었지만, 이걸 이용하는 건 추천하지 않는다.
왜냐하면 magrittr의 pipe와 쉽게 헷갈리기 때문이다.
다음의 shortcut은 random data를 만드는데 있어 굉장히 유용하다.
x <- map(1:3, ~ runif(2))
str(x)
## List of 3
## $ : num [1:2] 0.912 0.237
## $ : num [1:2] 0.011 0.203
## $ : num [1:2] 0.951 0.76
짧고 간단한 함수들에 사용할 걸 대비해 이 사용법을 익혀두자.
한 줄이 넘어갈 정도로 길어지거나 {}을 사용할 정도가 되면, name을 붙여줄 때가 된 것이다.
벡터vector에서 element를 추출하는데에도 shortcut이 있는데, purrr::pluck()으로 power된다.
element를 이름으로 추출할 수도, 몇 번째 position에 있느냐를 바탕으로 숫자로 추출할 수도, 리스트에서 둘 다를 이용해서 추출할 수도 있다.
이건 JSON에서 종종 일어나는, deeply nested list랑 작업할 때 편하다.
x <- list(
list(-1, x = 1, y = c(2), z = "a"),
list(-2, x = 4, y = c(5, 6), z = "b"),
list(-3, x = 8, y = c(9, 10, 11))
)
# 이름으로 추출하기
map_dbl(x, "x")
## [1] 1 4 8
# position으로 추출하기
map_dbl(x, 1)
## [1] -1 -2 -3
# 둘 다 이용해서 추출하기
map_dbl(x, list("y", 1))
## [1] 2 5 9
# 만약에 해당하는 곳에 component가 없다면 에러가 나옴
map_chr(x, "z")
## Error: Result 3 is not a length 1 atomic vector
# 디폴트를 제공해놓으면 그 값이 나옴
map_chr(x, "z", .default = NA)
## [1] "a" "b" NA
base R에서는
lapply()와 같은 base R 함수들도, 이름을 string으로 니가 제공해줄 수는 있다.
n base R functions, like lapply(), you can provide the name of the function as a string.
하지만 별로 유용하지는 않은게, lapply(x, "f")는 거의 항상 lapply(x, f)와 같고,
타이핑만 늘어날 뿐이기 때문이다.
9.2.3 Passing argument with ...
니가 호출하는 함수에다가 추가적인 인자들additional arguments을 패스해놓는 것은 종종 유용하다.
예를 들어, mean()이라는 함수에다가 na.rm = TRUE를 패스하고 싶다고 치자.
하나의 방법은 anonymous 함수를 이용하는 것이다.
x <- list(1:5, c(1:10, NA))
map_dbl(x, ~ mean(.x, na.rm = TRUE))
## [1] 3.0 5.5
하지만 map 함수들은 ...를 패스해줄 수 있기 때문에, 더 간단한 form이 가능하다.
map_dbl(x, mean, na.rm = TRUE)
## [1] 3.0 5.5
그림을 보면 더 쉽게 이해가 가능하다.
f 다음에 나오면, 어떠한 arguments건, map()은 데이터에다가 f()를 하고, 그 다음에 넣어준다.
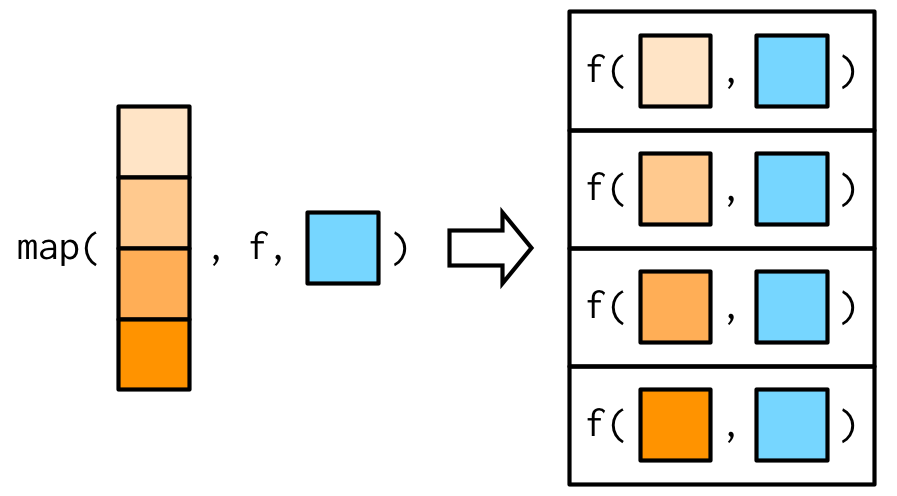
중요한 점은, 이 패스되는 arguments들은 decompose되지 않는다는 것이다.
map()에서 첫 번째로 넣어지는 arguments들은 decompose되었는데, 패스되는 additional arguments들은 decompose되지 않는다.
그림을 보고 제대로 이해하자.
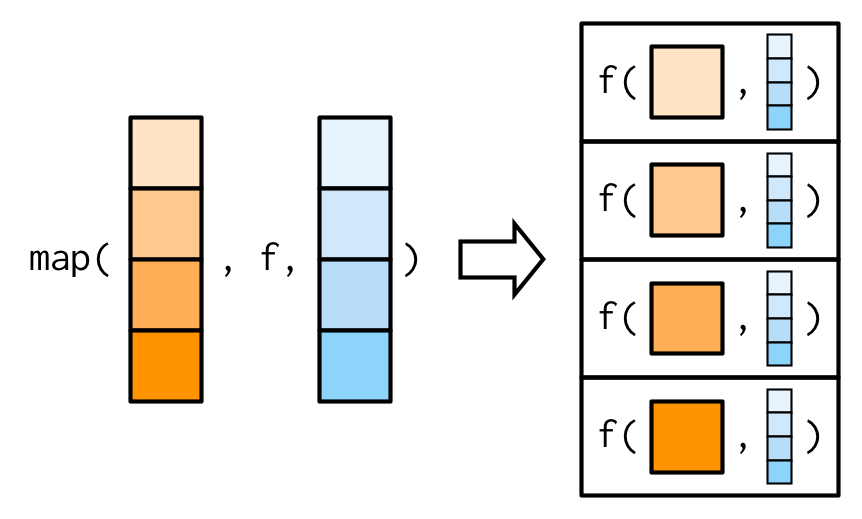
additional arguments도 decompose되는 것은 Section 9.4.2와 Section 9.4.5에서 배울 것이다.
map variants에서.
map()에다가 이렇게 additional arguments를 패스해놓는 것이랑, anonymous 함수를 이용해서 거기에다가 extra argument를 넣어놓는 것이랑은 미묘하게 다르다.
전자는 map()이 실행될 때 한 번만 evaluate되고,
후자는 f()가 실행될 때마다 새롭게 evaluate된다. map()이 불러질 때 한번만 evaluate되는 것이 아니라.
다음의 예를 보면 이해가 된다.
plus <- function(x, y) x + y
x <- c(0, 0, 0, 0)
map_dbl(x, plus, runif(1))
## [1] 0.06421859 0.06421859 0.06421859 0.06421859
map_dbl(x, ~ plus(.x, runif(1)))
## [1] 0.9007976 0.9012212 0.3127752 0.3242856
9.2.4 Argument names
한 줄 요약: 여기서는 argument names를 써주자 하는 것, 그리고 왜x나 f 대신에 .x, .f를 사용하는지를 알게 된다.
다이어그램에서는, 전반적인 구조를 이해하라고 argument names를 다 생략해놨었다.
하지만 작성하는 코드에서는, 읽기 쉬게끔, full names를 다 써놓기를 권장한다.
예를 들어, map(x, mean, 0.1)은 완벽하게 유효한valid 코드이지만, mean(x[[1]], 0.1)이란 뜻이고,
읽는 사람은 mean()의 두 번째 argument는 trim이란 걸 기억해야 한다.
읽는 사람이 불필요하게 remind하느라 고생하지 않도록, map(x, mean, trim = 0.1)이라고 써주자.
이게 map()의 arguments들이 좀 이상해보이는 이유다.
x, f라고 안 쓰고, .x, .f라고 쓴다.
왜 이렇게 하는지 예를 들어서 보여주겠다.
위에 map()이 어떻게 implement되었는지를 간단하게 보인, simple_map()을 다시 봐보자.
simple_map <- function(x, f, ...) {
out <- vector("list", length(x))
for (i in seq_along(x)) {
out[[i]] <- f(x[[i]], ...)
}
out
}
그리고 bootstrap_summary()라는 함수가 있다.
bootstrap_summary <- function(x, f) {
f(sample(x, replace = TRUE))
}
simple_map(mtcars, bootstrap_summary, f = mean)
## Error in mean.default(x[[i]], ...): 'trim' must be numeric of length one
왜 이런 에러가 발생하는걸까?
simple_map()을 호출한다는건 simple_map(x = mtcars, f = mean, bootstrap_summary)이랑 같은 것이고,
named 매칭이랑 positional 매칭이랑 충돌한다.
purrr 함수들은 이러한 충돌의 가능성을, 흔히 사용하는 x, f 대신에 .x, .f를 사용함으로써, 줄였다.
물론, 이러한 테크닉은 완벽하진 않다. (여전히 .x, .f를 이용하는 함수도 있을테니깐)
하지만 이러면 99퍼센트는 문제를 회피할 수 있다.
여전히 남은 1퍼센트의 경우에 있어서는 anonymous 함수를 사용하자.
base R에서는
...를 사용하는 base 함수들은, 이런 원치 않는 argument 매칭을 피하기 위해 여러가지 naming convention을 사용한다.
1. apply 함수들은 대부분 대문자를 사용함. ex) X, FUN
2. transform()는 \_라는 좀 더 이색적인exotic 접두사prefix를 사용한다.
이러면 이름이 더 비문법적non-syntatic이 되기 때문에, \`로 감싸줘야한다. Section 2.2.1에서 나왔던대로.
이러면 원치않은 매칭이 일어날 일이 극히 줄어든다.
3. 다른 functionals들, uniroot()나 optim()은 충돌을 피하기 위한 아무런 노력도 하지 않지만,
특별히 만들어진 함수들을 사용하기 때문에, 충돌이 일어날 일이 적다.
9.2.5 Varying another argument
이 때까지, map()의 첫 번째 argument는, 항상 function의 첫 번째 argument가 되었다.
하지만, 만약에 첫 번째 argument는 일정constant하고, different argument가 변하기vary를 바란다면?
그림으로 따지자면 다음과 같이.
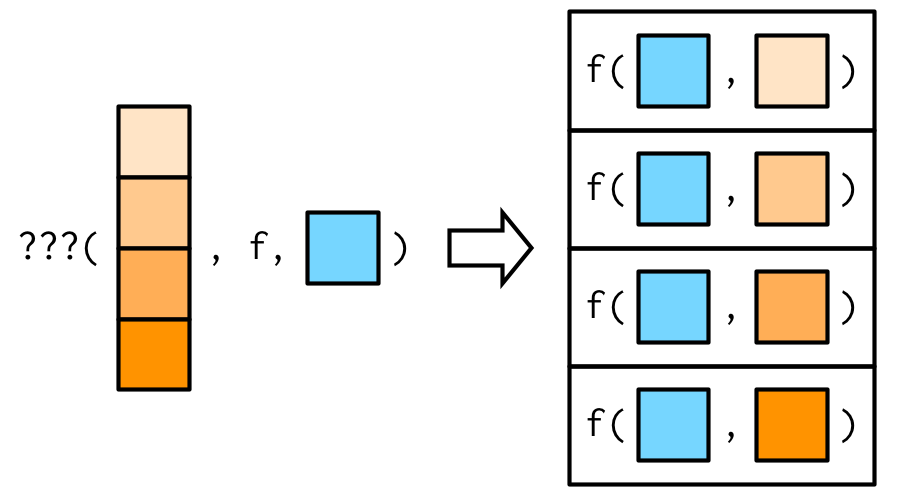
직접적으로 하는 방법은 없다. 하지만 대신에, 2가지 트릭을 이용해 할 수 있다.
이 예를 좀 묘사illustrate해보자면, 좀 일반적이지 않은 그런 값들이 있는 벡터가 있고,
mean을 구하는데 있어, triming에다가 다른 값들을 넣어가며 탐구를 해보고 싶다치자.
이 경우에, mean()의 first argument는 일정constant하고, trim이라는 second argument가 vary하기를 원하는 거다.
trims <- c(0, 0.1, 0.2, 0.5)
x <- rcauchy(1000)
. 가장 간단한 방법은, argument order를 rearrange하는 anonymous function을 사용하는 것.
map_dbl(trims, ~ mean(x, trim = .x))
## [1] -4.54874441 -0.10821502 -0.07687378 -0.08387444
그런데 얘는 x와 .x를 둘 다 사용하고 있기 때문에, 헷갈린다.
~ 사용하는 걸 포기함으로써 좀 더 깔끔하게 만들 수 있다.
map_dbl(trims, function(trim) mean(x, trim = trim))
## [1] -4.54874441 -0.10821502 -0.07687378 -0.08387444
. 우리는 알고 있는게 너무 많기에, R의 flexible argument 매칭 룰을 사용할 수도 있다.
예를 들어, mean(x, trim = 0.1)을 mean(0.1, x = x)라고 쓸 수도 있는데, 이렇게 map_dbl()을 call하는거다.
map_dbl(trims, mean, x = x)
## [1] -4.54874441 -0.10821502 -0.07687378 -0.08387444
그런데 이 방법technique은 추천하지 않는다.
왜냐하면, 독자가 .f의 argument order와 R의 argument matching rules를 둘 다 이해하고 있다는 가정 하에 하는 것이기 때문.
. Section 9.4.5에서 배울 pmap()을 쓰는 방법도 있다.
9.3 Purrr style
더 많은 map 변형들variants을 탐구해보기 전에,
상당히 현실적인 문제들을, 여러 개의 purrr 함수들을 사용해서 어떻게 해결하는지 봐보자.
이 toy example에서, 각 subgroup에 대한 model을 fitting하고, 모델의 계수를 추출해볼 것이다.
mtcars 데이터를 cylinders의 개수에 따라, base::split() 함수를 이용해, 그룹으로 쪼개자.
by_cyl <- split(mtcars, mtcars$cyl)
이러면 3개의 데이터 프레임들을 갖고 있는 list가 생긴다. 각각 4, 6, 8개의 cylinders를 갖고 있는 차들.
이제 각각에 대해 linear model을 fit하고, 두 번째 계수, 즉, slope를 추출하고 싶다고 하자.
다음은 purrr을 통해 어떻게 해야할지를 보여준다.
by_cyl %>%
map(~ lm(mpg ~ wt, data = .x)) %>%
map(coef) %>%
map_dbl(2) # intercept를 얻고 싶었다면 1을 넣었겠지.
## 4 6 8
## -5.647025 -2.780106 -2.192438
(%>%라는 pipe를 본 적이 없다면, Section 6.3에 설명되어 있다.)
각 line이 하나의 step을 요약encapsulate하고 있기 때문에, 쉽게 이 functional 뭐하고 있는지를 구분할 수 있고,
purrrr helpers들이 우리가 각 step에서 뭘 해야하는지를 간결하게 묘사하고 있다.
그래서 위 코드가 쉽다.
and the purrr helpers allow us / to very concisely describe / what to do in each step.
base R로는 이 문제를 어떻게 풀 수 있을까?
분명히 위의 각 purrr 함수를 동등한 base 함수로 대체할 수 있다.
by_cyl %>%
lapply(function(data) lm(mpg ~ wt, data = data)) %>%
lapply(coef) %>%
vapply(function(x) x[[2]], double(1))
## 4 6 8
## -5.647025 -2.780106 -2.192438
하지만, pipe를 쓰고 있기 때문에 진짜 base R만을 쓴 것은 아니다.
순수하게 base R로만 하려고 하면, 중간과정을 넣어야하고, 각 step에서 뭔가를 조금 더 해야한다.
models <- lapply(by_cyl, function(data) lm(mpg ~ wt, data = data))
vapply(models, function(x) coef(x)[[2]], double(1))
## 4 6 8
## -5.647025 -2.780106 -2.192438
혹은, 물론 for 루프를 사용할 수도 있다.
intercepts <- double(length(by_cyl))
for (i in seq_along(by_cyl)) {
model <- lm(mpg ~ wt, data = by_cyl[[i]])
intercepts[[i]] <- coef(model)[[2]]
}
intercepts
## [1] -5.647025 -2.780106 -2.192438
purrr에서, apply 함수로, for 루프로, 옮겨가면서 더 많은 iteration을 해야한다는 걸 볼 수 있다.
purrr에서는 map(), map(), map_dbl()으로 총 3번 iterate
apply 함수들은 lapply(), vapply()로 총 2번 iterate
for 루프문을 이용했을 때는 한 번 iterate
잉? 더 많이 iterate할수록 별로인게 아닌가요?
아니다.
각 스텝이 더 많고(줄이 많고) 간단할수록, 코드를 더 이해하기 쉽고 나중에 수정하기도 편해서 좋다.
9.4 Map variants
map()의 주요 변형primary variants으로는 총 23개가 있다.
이 때까지 5개를 배웠고, (map(), map_lgl(), map_int(), map_dbl(), map_chr())
이 말인즉슨 18개 남았다는 뜻. (...)
하지만 다 따로 배워야하는 건 아니고, 5개의 새로운 아이디어만 배우면 되게끔 purrr을 디자인했다.
- output이 input과 같은 타입type이 되도록,
modify() - 2개의 inputs에 대해 iterate하도록,
map2() - index를 이용해서 iterate하도록,
imap() - 아무것도 return하지 않도록,
walk() - 몇 개의 input이 되든 상관없이 iterate하도록,
pmap()
map family의 함수들은, orthogonal한 input과 output을 갖고 있는데,
이 말인즉슨 모든 family를 inputs를 행에, outputs를 열에 두고서, 행렬matrix로 조직organise해볼 수 있다는 거다.
row에 있는 아이디어를 이해하고 나면, column에 있는 것과 결합시킬 수 있다.
column에 있는 아이디어를 이해하고 나면, row에 있는 것과 결합시킬 수 있다.
| List | Atomic | Same type | Nothing | |
|---|---|---|---|---|
| One argument | map() |
map_lgl(), ... |
modify() |
walk() |
| Two arguments | map2() |
map2_lgl(), ... |
modify2() |
walk2() |
| One argument + index | imap() |
imap_lgl(), ... |
imodify() |
iwalk() |
| N arguments | pmap() |
pmap_lgl(), ... |
- | pwalk() |
9.4.1 Same type of output as input: modify()
이 때까지 했던 map()은 리스트를 return했었음.
map_*()들은 접미사suffix에 따라 output이 어떤 타입일지 예상이 가능했었고.
그런데 이제는 input과 같은 type의 output을 가지고 싶을 때가 문제. 예를 들어보자.
데이터 프레임이 있는데, 모든 칼럼을 2배하고 싶다치자.
했던대로 map()을 쓰면, 얘는 항상 리스트로 return을 한다.
df <- data.frame(
x = 1:3,
y = 6:4
)
df
## x y
## 1 1 6
## 2 2 5
## 3 3 4
map(df, ~ .x * 2)
## $x
## [1] 2 4 6
##
## $y
## [1] 12 10 8
output도 여전히 데이터 프레임으로 유지keep하고 싶을 때, modify()를 사용하는 것.
항상 input과 같은 타입의 output을 return한다.
modify(df, ~.x * 2)
## x y
## 1 2 12
## 2 4 10
## 3 6 8
이름과는 달리, 데이터를 수정하지는 않음. modified copy를 return한다는 뜻.
그러니깐 따로 저장해줘야 한다.
현재 것을 진짜로 modify하고 싶다면 따로 assign해야한다.
이전의 map()과 같이, modify()의 implementation도 간단하다.
사실 map()보다 쉽다.
왜냐하면 새로운 output vector를 만들 필요도 없이, input을 replace하면 되기 때문이다.
(실제 코드는 예외적인 경우들을 우아하게 다루기 위해, 좀 더 복잡하다.)
simple_modify <- function(x, f, ...) {
for ( i in seq_along(x)) {
x[[i]] <- f(x[[i]], ...)
}
x
}
Section 9.6.2에서, modify()의 매우 유용한 변형variant인 modify_if()를 배울 것이다.
이건 데이터 프레임의 numeric 칼럼만 골라서 2배 할 수 있게 해준다.
modify_if(df, is.numeric, ~ .x * 2)
## x y
## 1 2 12
## 2 4 10
## 3 6 8
9.4.2 Two inputs: map2() and friends
map()은 single argument인 .x에 대해 vectorised over한다.
즉, .f가 호출될 때마다 오직 .x만이 달라지고 있고, 다른 pass along되는 arguments들은 바뀌지 않는다.
그래서 몇몇 문제에 관해서는 별로다.
예를 들어서, 관측치들의 리스트에 대해서, weights의 리스트가 따로 있어 weighted mean을 구하고 싶다면?
xs <- map(1:8, ~ runif(10))
xs[[1]][[1]] <- NA
ws <- map(1:8, ~ rpois(10, 5) + 1)
map_dbl()을 사용해서 unweighted means를 구할 수는 있다.
map_dbl(xs, mean)
## [1] NA 0.5892760 0.5034291 0.4248445 0.5497616 0.5574805 0.4243072
## [8] 0.4092384
ws를 additional arguments로 passing하는 걸로는 안 된다.
왜냐하면 .f 뒤에 나오는 arguments는 transformed되지 않기 때문이다.
map_dbl(xs, weighted.mean, w = ws)
## Error in weighted.mean.default(.x[[i]], ...): 'x' and 'w' must have the same length
그림으로 표현하자면, 이런 식으로.
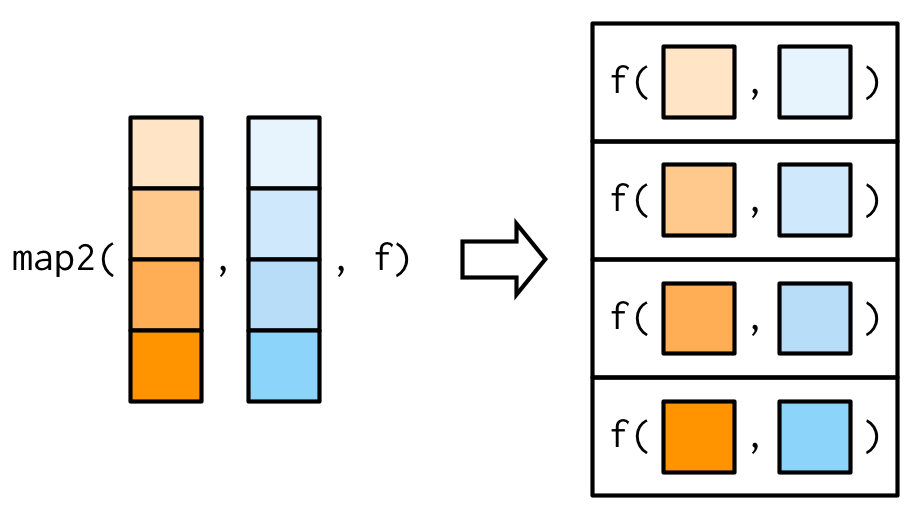
그래서, 이제는 새로운 툴이 필요하다: map2()
얘는 two arguments를 vectorised over한다.
이 말인즉슨, .x와 .y 둘 다 .f의 각 call에서 변화한다.
This means both .x and .y are varied in each call to .f.
map2_dbl(xs, ws, weighted.mean)
## [1] NA 0.5798521 0.4788945 0.4410043 0.5869418 0.4899314 0.3719651
## [8] 0.4415888
그림으로 표현하면, 이렇게.
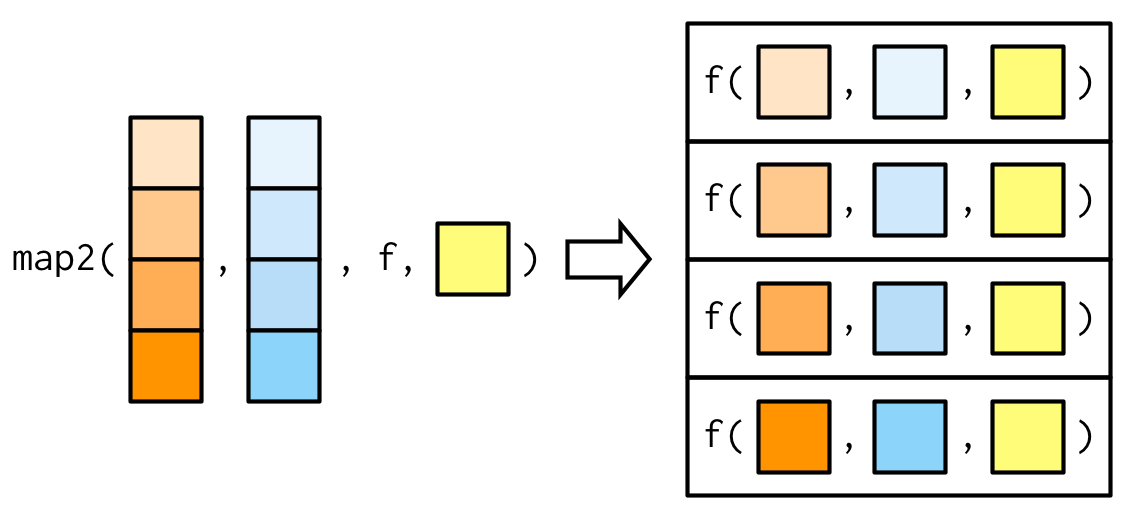
그리고 additional arguments도 그냥 똑같이 .f 다음에 넣어주면 된다.
map2_dbl(xs, ws, weighted.mean, na.rm = TRUE)
## [1] 0.4496569 0.5798521 0.4788945 0.4410043 0.5869418 0.4899314 0.3719651
## [8] 0.4415888
그림으로 표현하면, 이렇게.
map2()의 기본적인 implementation은 간단하고, map()의 implementation과 꽤나 비슷하다.
하나의 벡터로만 iterating over하는 것이 아니라, 2개를 병렬parallel로 iterate한다.
simple_map2 <- function(x, y, f, ...) {
out <- vector("list", length(x))
for(i in seq_along(x)) {
out[[i]] <- f(x[[i]], y[[i]], ...)
}
out
}
실제 map2()와 위의 간단한 함수와의 차이는, map2()는 y의 길이가 짧을 경우, inputs를 recycles해서 같은 길이가 되도록 한다는거.
그래서 경우에 따라, map2(x, y, f)는 자동적으로 map(x, f, y)와 똑같이 행동하게 된다.
함수에 따라 도움이 되긴하는데, 최대한 더 간단한 form을 쓰자.
base R에서는
map2()와 가장 비슷한 것은 Map()이다. Section 9.4.5에서 다룰 것이다.
사실 별로 안 다루더라. base R꺼는 그냥 있다고만 알아두는게 편함.
9.4.3 No outputs: walk() and friends
대부분의 함수들은, return되는 값을 얻기 위해서 호출call을 한다.
그래서 map() 함수를 이용해서 값을 캡쳐하고 저장하는건, 말이 된다.
하지만 몇몇 함수들은 side-effects를 위해서 호출된다. (예를 들어, cat(), write.csv(), ggsave())
그리고 그 결과를 캡쳐한다는건 말이 안 된다.
cat()을 이용해서 웰컴 메세지를 보여주는, 간단한 예를 보자.
cat()은 NULL을 return하기 때문에,
map()이 작동하는 동안(우리가 원하는 웰컴들을 만드는 동안), list(NULL, NULL)도 return하고 있다.
welcome <- function(x) {
cat("Welcome ", x, "!\n", sep = "")
}
names <- c("Hadley", "Jenny")
map(names, welcome)
## Welcome Hadley!
## Welcome Jenny!
## [[1]]
## NULL
##
## [[2]]
## NULL
이렇게, 웰컴들을 만드는 것 말고도, cat()의 return값도 보여준다.
이러한 문제를, map()의 결과물result을 절대 사용하지 않을 변수에다가 assign함으로써 회피avoid할 수 있다.
하지만 이러면 코드의 의도가 지저분해진다.
대신에 purrr에 있는 walk family의 함수들을 사용하면,
.f의 return 값들을 무시하고 대신에 .x를 invisibly하게 return한다.
walk(names, welcome)
## Welcome Hadley!
## Welcome Jenny!
다음의 그림에, map()과의 중요한 차이점을 보여주려고 노력해놨다.
outputs는 ephemeral, input이 invisibly하게 return된다.
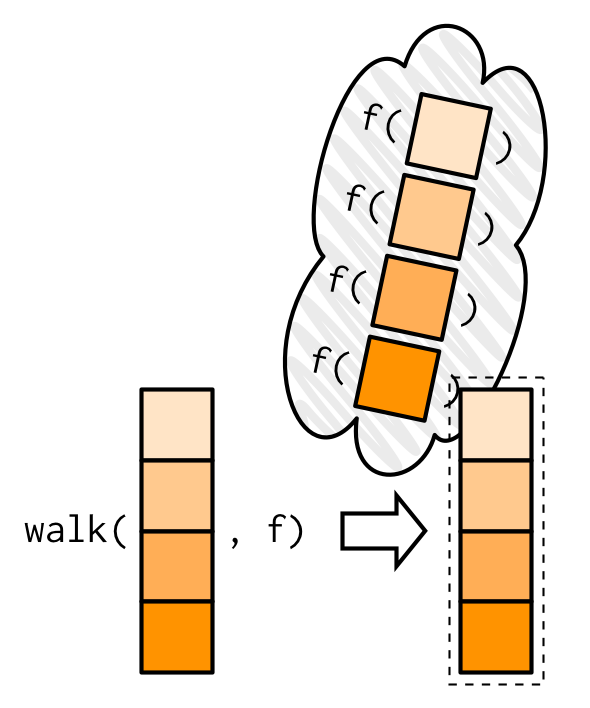
walk()의 가장 유용한 변형variant은 walk2()다.
왜냐하면, 매우 흔한 side-effect는 무언가를 디스크에 저장하는 것.
그리고 무엇인가 저장할 때 항상 2개의 값이 필요하다. object랑, 저장할 경로.
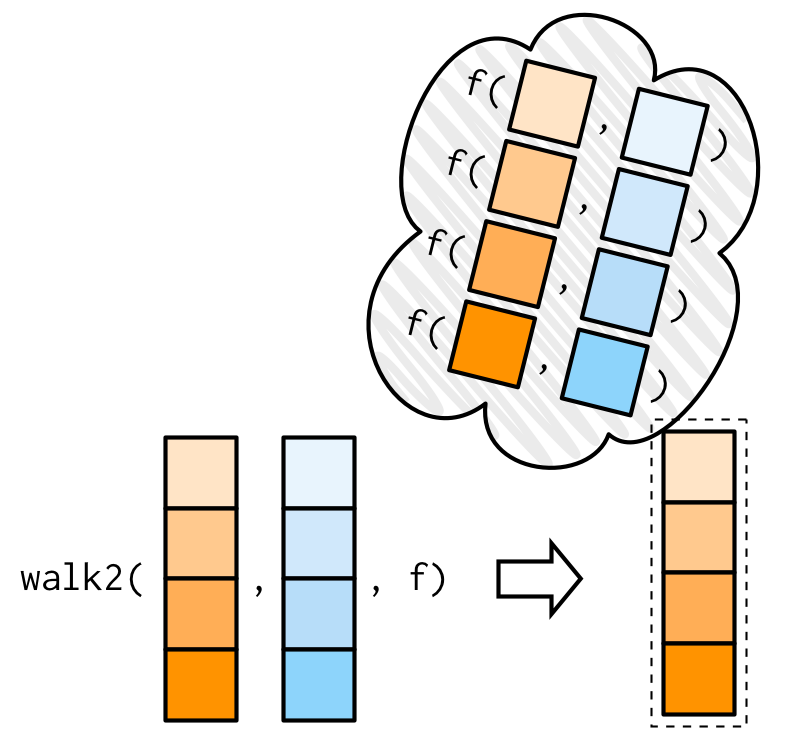
예를 들어, 데이터 프레임들의 리스트를 가지고 있고, (여기서는 split()을 이용해서 만들었음)
각각을 separate CSV 파일로 저장하고 싶다고 하자. walk2()를 이용하면 쉽다.
temp <- tempfile()
dir.create(temp)
cyls <- split(mtcars, mtcars$cyl)
paths <- file.path(temp, paste0("cyl-", names(cyls), ".csv"))
walk2(cyls, paths, write.csv)
dir(temp)
## [1] "cyl-4.csv" "cyl-6.csv" "cyl-8.csv"
여기서 walk2()를 쓴 것은, write.csv(cyls[[1]], paths[[1]]), write.csv(cyls[[2]], paths[[2]]), write.csv(cyls[[3]], paths[[3]])를 한 것이랑 같다.
base R에서는
walk()랑 비슷한 것은 없다.
lapply()의 결과물을 invisible()으로 감싸거나, 사용하지 않을 변수에다가 저장해야 한다.
9.4.4 Iterating over values and indices
for 루프에서 loop over하게 하는데에는 기본적으로 3가지 방법이 있다.
1) elements들에 대해 loop over: for (x in xs)
2) numeric indices에 대해 loop over: for (i in seq_along(xs))
3) names에 대해 loop over: for (nm in names(xs))
첫 번째 형식은 map() family와 유사하다.
두 번째, 세 번째 형식은 imap() family와 유사하다.
값들과 인덱스들을 병렬parallel로 iterate over할 수 있게끔 해준다는 점에서.
.f가 2개의 arguments와 함께 호출된다는 점에서, imap()은 map2()와 비슷하다.
하지만 imap()은 이 2개의 arguments가, 하나의 vector에서 나왔다는 점에서 다르다.
만약 x가 names를 갖고 있으면, imap(x, f)는 map2(x, names(x), f)와 같다.
만약 x가 names가 없으면, imap(x, f)는 map2(x, seq_along(x), f)와 같다.
imap()은 라벨들labels을 붙일 때도 종종 유용하다.
imap_chr(iris, ~ paste0("The first value of ", .y, " is ", .x[[1]]))
## Sepal.Length
## "The first value of Sepal.Length is 5.1"
## Sepal.Width
## "The first value of Sepal.Width is 3.5"
## Petal.Length
## "The first value of Petal.Length is 1.4"
## Petal.Width
## "The first value of Petal.Width is 0.2"
## Species
## "The first value of Species is setosa"
만약 벡터가 unnamed라면, 두 번째 argument는 index가 될 것이다.
x <- map(1:6, ~ sample(1000, 10))
imap_chr(x, ~ paste0("The highest value of ", .y, " is ", max(.x)))
## [1] "The highest value of 1 is 951" "The highest value of 2 is 905"
## [3] "The highest value of 3 is 931" "The highest value of 4 is 989"
## [5] "The highest value of 5 is 954" "The highest value of 6 is 849"
imap()은, 벡터안에 있는 값들을, 포지션에 따라서 작업하고 싶을 때 유용한 helper이다.
imap() is a useful helper if you want to work with the values in a vector / along with their positions.
9.4.5 Any number of inputs: pmap() and friends
map(), map2()이 있으니깐, map3(), map4(), map5()도 있을 것. 하지만 이런 식으로 가면 안 끝난다.
map2()를 arguments 수를 arbitrary한 것으로 일반화시키기보다는, purrr은 pmap()을 이용해 접근.
arguments가 몇 개이던간에, single list만 input으로 supply해주면 된다.
대부분의 케이스에, 같은 길이를 갖는 벡터들의 리스트. 즉, 데이터 프레임과 매우 유사할 것이다.
다음의 그림에 그 관계를 최대한 강조해보았다.
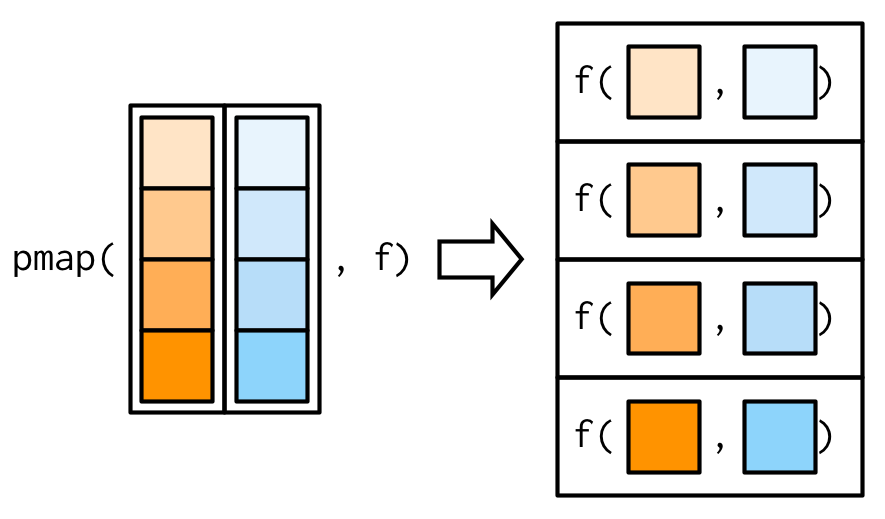
그래서, map2()와 pmap()간의 간단한 equivalence가 성립한다.
map2(x, y, f)는 pmap(list(x, y), f)와 같은 것이다.
위에서 map2_dbl(xs, ws, weighted.mean)과 동등한 구조가 되도록 pmap()으로 써보면,
pmap_dbl(list(xs, ws), weighted.mean)
## [1] NA 0.5798521 0.4788945 0.4410043 0.5869418 0.4899314 0.3719651
## [8] 0.4415888
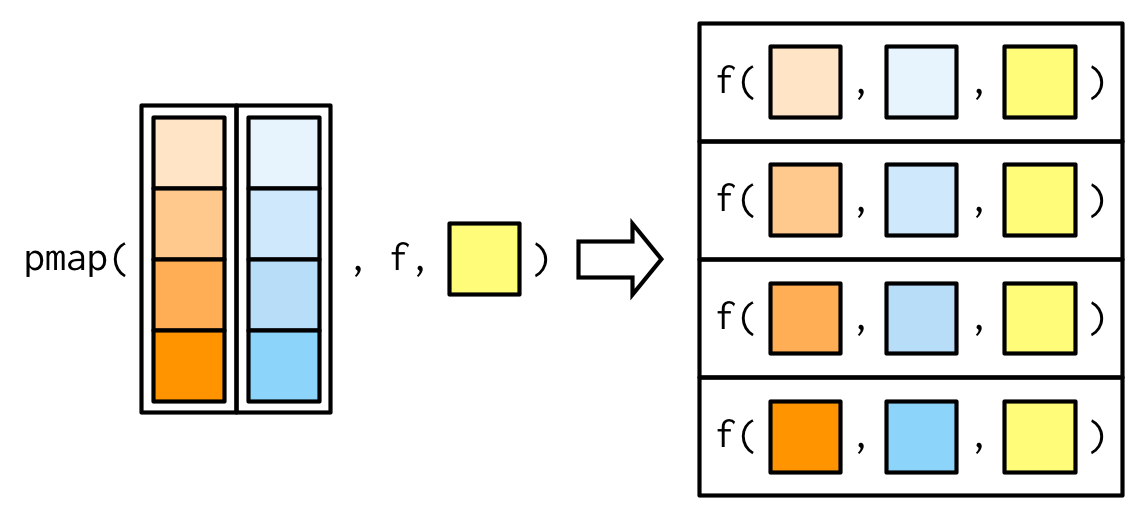
이전과 마찬가지로, varying arguments는 .f 이전에 나와야 하고(이제는 리스트 안에 넣어줘야함),
constant arguments는 .f 이후에 나와야 한다.
pmap_dbl(list(xs, ws), weighted.mean, na.rm = TRUE)
## [1] 0.4496569 0.5798521 0.4788945 0.4410043 0.5869418 0.4899314 0.3719651
## [8] 0.4415888
pmap()과 다른 map 함수들과의 가장 큰 차이점은,
pmap()은 argument matching에 있어 더 쉬운 컨트롤이 가능하다는 것.
왜냐하면 리스트의 components에다가 이름을 붙일 수 있기 때문.
Section 9.2.5에서 했던, trim을 다르게 줘서 mean 구하던 예로 따지면, x에다가 varying argument인 trim을 주고 싶었다.
이걸 pmap()으로 해보면,
trim <- c(0, 0.1, 0.2, 0.5)
x <- rcauchy(1000)
pmap_dbl(list(trim = trims), mean, x = x)
## [1] -13.39978986 -0.01773796 -0.02250029 -0.03806866
리스트의 components에다가 이름을 붙이는 건 매우 좋은 습관이라고 생각을 한다.
왜냐하면 어떻게 함수가 호출되는지가how the function will be called 매우 명확해지기 때문.
pmap()을 (리스트가 아닌)데이터 프레임과 함께 호출하는 것도 편리하다.
데이터 프레임을 만드는 편리한 방법 중 하나는, tibble::tribble()을 사용하는 것.
이걸 사용하면 기존의 column-by-column이 아닌 row-by-row로 묘사describe가 가능.
함수에 대한 parameters를 데이터 프레임으로 생각해보는 건, 매우 강력한 패턴이다.
thinking about the parameters to a function as a data frame is a very powerful pattern.
다음의 예는, varying parameters에 대해 random uniform numbers를 뽑는 걸 보여주고 있음.
params <- tibble::tribble(
~ n, ~ min, ~ max,
1L, 0, 1,
2L, 10, 100,
3L, 100, 1000
)
pmap(params, runif)
## [[1]]
## [1] 0.4798659
##
## [[2]]
## [1] 56.73305 40.79984
##
## [[3]]
## [1] 685.3166 589.5046 367.1096
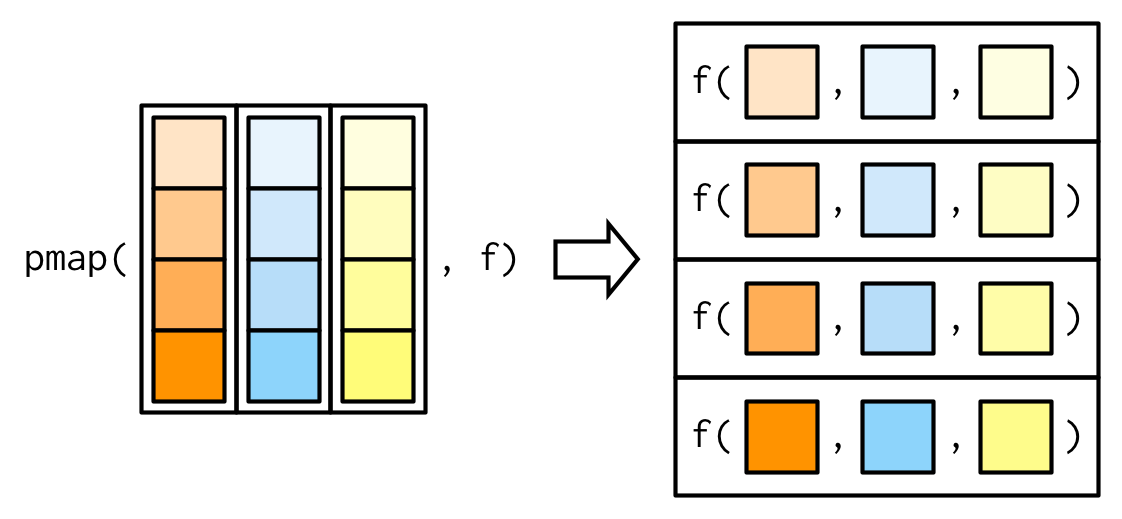
여기서, column names는 중요하다. runif()의 arguments를 맞춰주기 위해서 저렇게 정했다.
그래서 pmap(params, runif)는, runif(n = 1L, min = 0, max = 1), runif(n = 2L, min = 10, max = 100), runif(n = 3L, min = 100, max = 1000)와 같은 것임.
만약에 데이터 프레임은 가지고 있는데, 이름들names이 매치가 안 된다면, dplyr::rename()이나 비슷한걸 써라.
base R에서는
pmap() 패밀리와 비슷한 것으로, Map()과 mapply()가 있다. 둘 다 심각한 단점이 있다.
1) Map()은 모든 arguments들에 대해 vectorise over하기 때문에, vary하지 않는 argument는 넣어줄 수 없다.
2) mapply()는 sapply()의 다차원 버전multidimensional version이다.
개념적으로 이건 Map()의 output을 받은 다음, 가능하면 간단하게simplifies 한다.
sapply()와 비슷한 문제가 생긴다. vapply()는 multi-input이 가능하지 않다.
9.5 Reduce family
map family 다음으로, 가장 중요한 함수 family는 reduce family다.
이 family는 훨씬 작고 2개의 main variants뿐이고, 훨씬 덜 사용되지만, powerful idea다.
이걸로 useful algebra를 효과적으로 다룰 수도 있고,
매우 큰 데이터셋을 처리할 때 자주 쓰는, map-reduce 프레임워크를 할 수 있다.
9.5.1 Basics
reduce()는 길이 n짜리 벡터를 받고, 한 번에 한 쌍의 값들을 함수 호출해서, 길이 1짜리 벡터를 생산한다.
produces a vector of length 1 / by calling a function / with a pair of values / at a time.
즉, reduce(1:4, f)라고 하면, 이건 f(f(f(1, 2) ,3), 4)와 같은 것임.
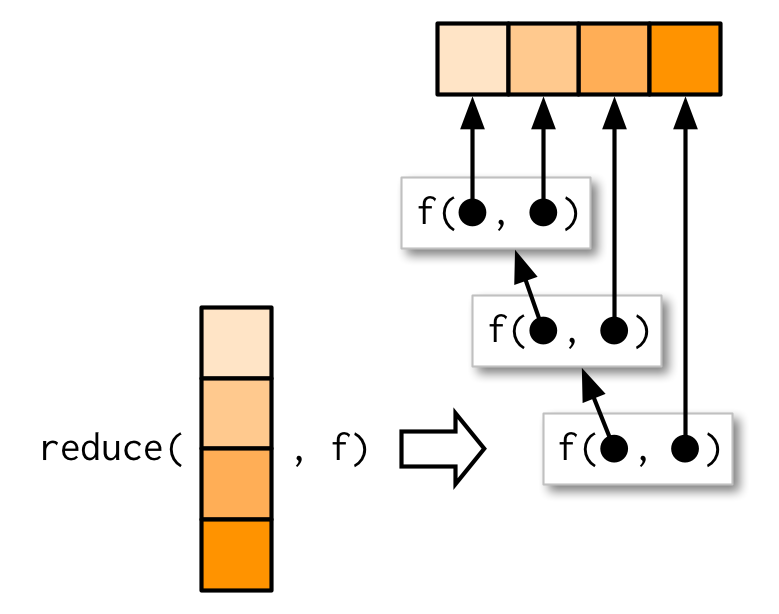
(난 이 그림이 맘에 들지 않는다. 화살표 방향이 반대가 되었어야한다고 생각한다.) reduce()는, 2개의 inputs로 작동하는 함수를 generalise해서,
inputs의 개수가 any number이 될 수 있도록 하기에 좋은 방법.
하나의 리스트에 여러 개의 numeric vector들이 있고,
모든 벡터들에 공통으로 있는 값을 찾고 싶다고 하자.
그러니까 예를 가지고 해보면,
l <- map(1:4, ~ sample(1:10, 15, replace = T))
str(l)
## List of 4
## $ : int [1:15] 9 7 4 1 3 5 1 4 7 8 ...
## $ : int [1:15] 7 7 9 2 2 6 3 7 8 9 ...
## $ : int [1:15] 3 4 3 5 6 8 2 8 1 10 ...
## $ : int [1:15] 8 8 9 4 8 10 5 9 4 6 ...
여기서 공통으로 존재하는 값들을 찾고 싶다는 것임.
이 문제를 해결하기 위해서는, intersect()가 반복적으로 필요하다.
out <- l[[1]]
out <- intersect(out, l[[2]])
out <- intersect(out, l[[3]])
out <- intersect(out, l[[4]])
out
## [1] 9 4 1 5 8
근데 이걸 reduce()를 쓰면 한 번에 해낼 수 있다.
reduce(l, intersect)
## [1] 9 4 1 5 8
그럼 리스트의 각 element에 한 번이라도 나타나는 값들을 알고 싶다면?
즉, 모든 벡터에 한 번이라도 나타나는 값들을 알고 싶다면?
intersect() 대신에 union()을 쓰면 됨.
reduce(l, union)
## [1] 9 7 4 1 3 5 8 2 6 10
map family와 같이, additional arguments를 패스해줄 수도 있다.
intersect(), union()은 extra arguments를 받지 않기 때문에 여기서 보여줄 수는 없지만,
원리는 단순하고 그림과 같이 나타내줄 수 있다.
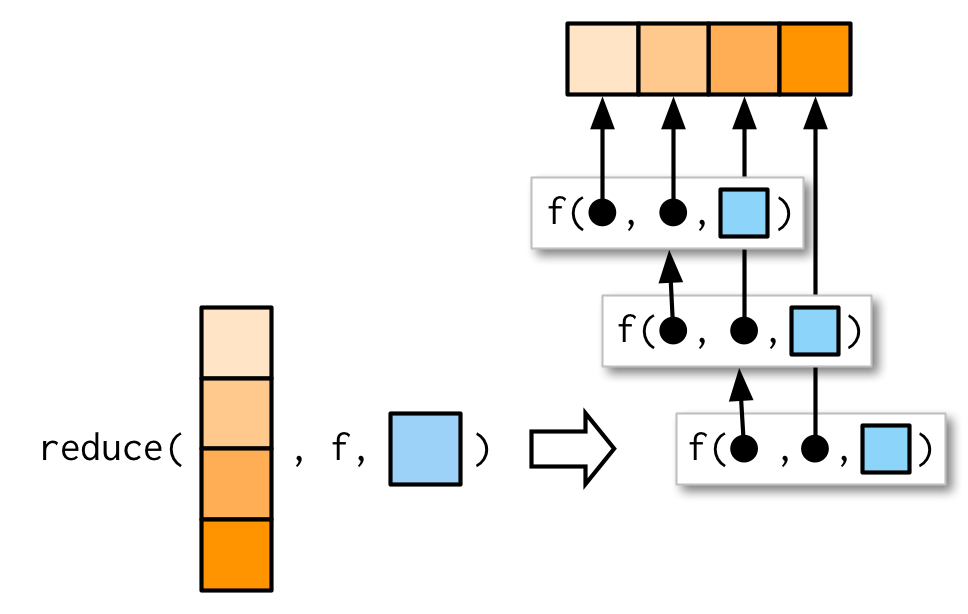
reduce()의 핵심은, for 루프에다가 simple wrapper을 한 것이다.
simple_reduce <- function(x, f) {
out <- x[[1]]
for (i in seq(2, length(x))) {
out <- f(out, x[[i]])
}
out
}
base R에서는
Reduce()가 있는데, argument 순서를 다르게 받는다.
여기서는 함수 먼저 받고, 그 다음에 벡터를 받고.
그리고 이 함수는 additional arguments를 공급해줄 방법이 없다.
9.5.2 Accumulate
reduce()의 첫 번째 변형variant은 accumulate()다.
이건 어떻게 reduce가 작동하는지 이해하기에 유용한 것.
왜냐하면 단순히 최종 결과물final result만 주지 않고, 중간중간 결과물들 또한 return해주기 때문.
accumulate(l, intersect)
## [[1]]
## [1] 9 7 4 1 3 5 1 4 7 8 1 7 3 4 9
##
## [[2]]
## [1] 9 7 4 1 3 5 8
##
## [[3]]
## [1] 9 4 1 3 5 8
##
## [[4]]
## [1] 9 4 1 5 8
sum()의 경우에는,
x <- c(4, 3, 10)
reduce(x, `+`)
## [1] 17
accumulate(x, `+`)
## [1] 4 7 17
9.5.3 Output types
위의 +를 사용한 예에서, x가 길이 1이거나 0이면, reduce()는 무엇을 return 해야할까?
additional arguments가 없다면, reduce()는 그냥 길이 1짜리 input을 그대로 return한다.
reduce(1, `+`)
## [1] 1
이 말인즉슨, input이 유효한지 따질 방법이 없다는 것이기도 하다.
reduce("a", `+`)
## [1] "a"
그럼 길이가 0이라면? .init argument를 이용하라는 에러를 얻게 된다.
reduce(integer(), `+`)
## Error: `.x` is empty, and no `.init` supplied
.init이 여기서는 무엇이 되야하는가?
이걸 알아보기 위해서는, .init이 주어졌을 때 무슨 일이 일어나는지 확인해보아야 한다. 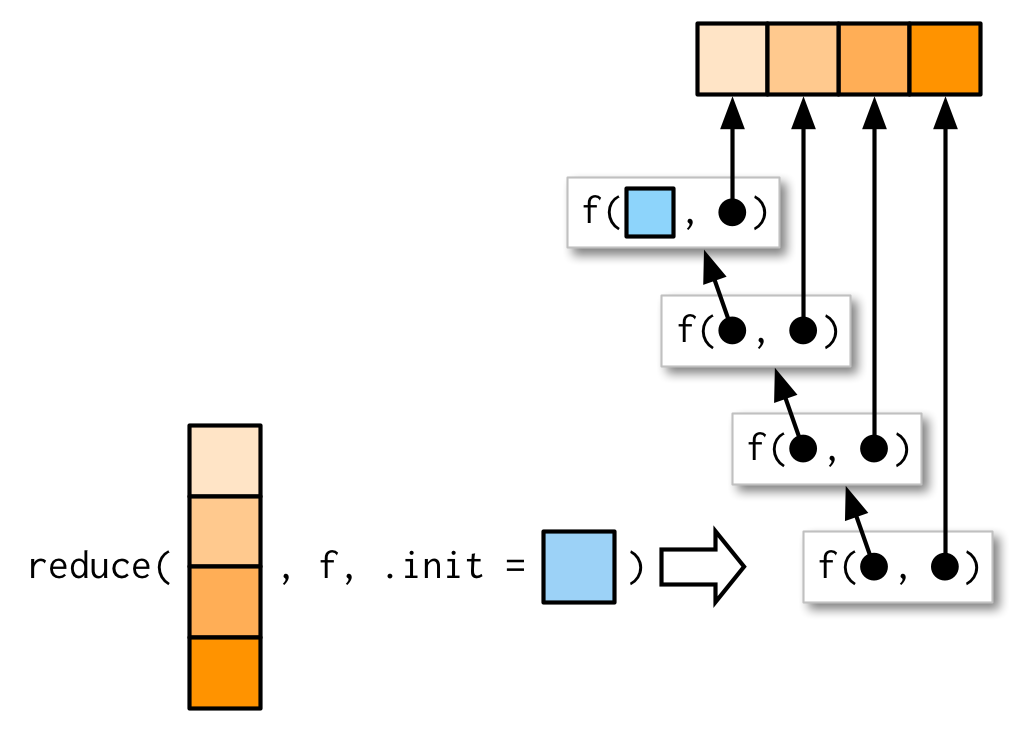
그래서, reduce(1, \+`, init)이라고 하면, 결과물은1 + init이 된다. <br /> result는 1이어야하니깐,.init`은 0이어야만 한다.
reduce(integer(), `+`, .init = 0)
## [1] 0
그리고 이걸로써 유효하지 않은 형식의 input을 넣었는지도 체크할 수가 있다.
reduce("a", `+`, .init = 0)
## Error in .x + .y: 이항연산자에 수치가 아닌 인수입니다
0이 identity of the real numbers under the operation of addition이기 때문. 항등원의 개념.
R은 summary 함수들이, zero length input에 대해서, 어떤 값을 return해야되는지에 대해, 위와 같은 원리를 적용해준다.
sum(integer()) # sum의 항등원은 0
## [1] 0
prod(integer()) # 곱의 항등원은 1
## [1] 1
min(integer()) # min의 항등원은 Inf
## [1] Inf
max(integer()) # max의 항등원은 -Inf
## [1] -Inf
reduce()를, 함수 안에다가 쓸 때면, .init을 항상 supply해줘야한다.
input으로 넣는 vector 길이가 0이나 1일 때는, 항상 결과물이 무엇이 되어야 하는지를 생각 잘해보고, implementation을 테스트해보자.
9.5.4 Multiple inputs
매우 가끔씩, 한 번에 2개의 arguments를 reducing하는 함수에다가 pass해줄 필요가 있다.
예를 들어, join together하고 싶은 데이터 프레임들의 리스트가 있다고 치자.
그리고 element의 변수 이름은 다 다르다고 치자.
굉장히 특수한 케이스라서 너무 시간을 쓰게하고 싶지는 않은데, reduce2()가 있다는건 알아두자.
.init이 supply되냐 아니냐에 따라 second argument의 길이가 달라진다.
만약 x의 elements가 4개면, f는 3번만 불러질 것이다.
init을 supply했다면, f는 4번 불러질 것이다.
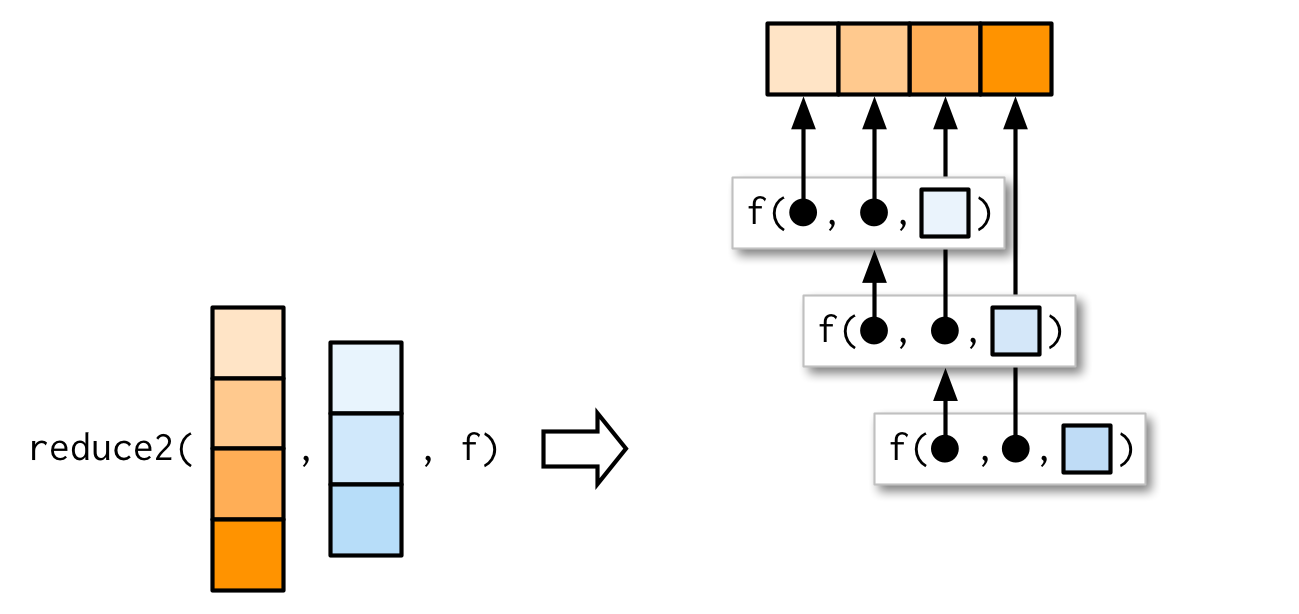
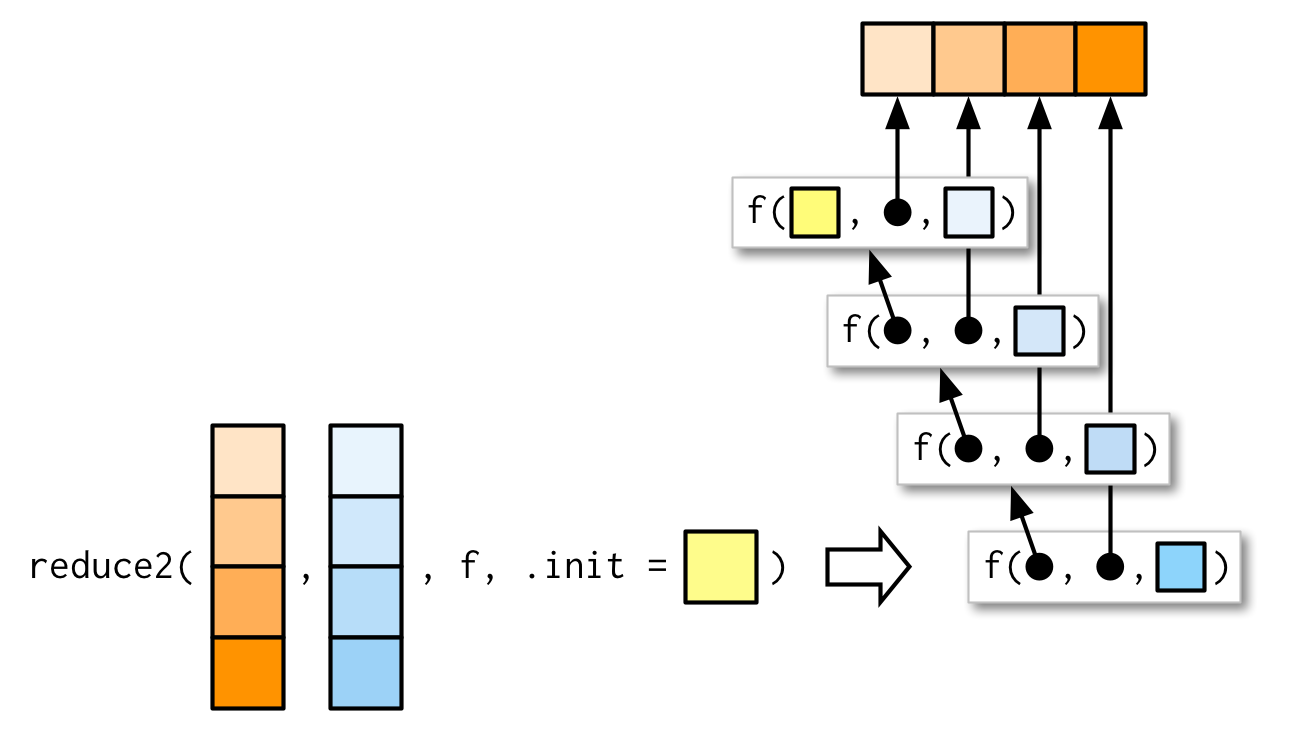
도대체 뭘 할 때 쓸모있을지조차 예상이 안 가서 이해가 안 된다. 와닿지가 않는듯.
reduce2() 사용법 몇 개에 대해 알아보긴했는데, 이게 필요한 순간조차 인지하지 못할 것 같으니 일단 남겨두자.
9.5.5 Map-reduce
Hadoop과 같은 기술을 만든 map-reduce에 대해 들어본 적이 있을 것이다.
이제 이 아이디어가 얼마나 간단하고 강력한지 알 수 있다.
map-reduce는 reduce와 map을 결합시킨 것.
큰 데이터가 갖는 차이점은, 데이터가 여러 개의 컴퓨터에 걸쳐있다는 것이다.
각 컴퓨터가 데이터에 map을 실행하고, coordinator에게 결과물을 return.
그래서 각 결과물을 하나의 결과물로 reduce.
간단한 예로, 엄청나게 큰 벡터의 평균을 계산하는 걸 상상해보자.
너무 커서 여러 개의 컴퓨터에 나누어서 저장되어 있다.
그럼 각 컴퓨터에게 sum과 length를 계산하게 한 다음, coordinator에게 return해주고,
coordinator가 overall mean을 계산하게끔 할 수 있다.
9.6 Predicate functionals
predicate라는 건 함수다. TRUE나 FALSE를 return하는 함수. is.character(), is.null(), all()과 같이.
그리고 predicate가 TRUE를 return하면, 벡터와 매치가 된다고 말을 한다.
9.6.1 Basics
predicate functional은 벡터의 각 element에다가 predicate를 적용한다.
A predicate functional / applies a predicate / to each element of a vector.
purrr은 3개의 쌍을 이루는, 총 6개의 유용한 함수들을 제공한다.
purrr provides six useful functions / which come in three pairs.
some(.x, .p)는 만약 하나의 element 매치가 있으면TRUE,every(.x, .p)는 모든 elements가 매치면TRUE
some(.x, .p)returnsTRUEif any element matches;every(.x, .p)returnsTRUEif all elements match.
이것들은 any(map_lgl(.x, .p))와 all(map_lgl(.x, .p))과 비슷하다.
하지만 더 빨리 끝나고, 계산이 더 빠름.
some()은 처음 TRUE가 발견된 순간 TRUE를 return,
every()는 처음 FALSE가 발견된 순간 FALSE를 return.
-
detect(.x, .p)은 첫 번째 매치의 값value을 return,
detect_index(.x, .p)은 첫 번째 매치의 location을 return. -
keep(.x, .p)는 모든 matching elements를 보존keep함,
discard(.x, .p)은 모든 matching elements를 버림drops.
다음의 예는 위의 functionals를 데이터 프레임에 어떻게 이용할 수 있는지 보여준다.
df <- data.frame(x = 1:3, y = c("a", "b", "c"))
df
## x y
## 1 1 a
## 2 2 b
## 3 3 c
detect(df, is.factor)
## [1] a b c
## Levels: a b c
detect_index(df, is.factor)
## [1] 2
keep(df, is.factor)
## y
## 1 a
## 2 b
## 3 c
discard(df, is.factor)
## x
## 1 1
## 2 2
## 3 3
이렇게 keep()이랑 discard()는 원래의 데이터 구조, 데이터 프레임이라는 것도 남겨준다.
9.6.2 Map variants
map()과 modify()는 predicate functions를 받을 수 있는 변형variants들이 있다.
.x의 elements를, .p가 TRUE일 때만, transforming하는 것임.
df <- data.frame(
num1 = c(0, 10, 20),
num2 = c(5, 6, 7),
chr1 = c("a", "b", "c"),
stringsAsFactors = FALSE
)
map_if(df, is.numeric, mean)
## $num1
## [1] 10
##
## $num2
## [1] 6
##
## $chr1
## [1] "a" "b" "c"
modify_if(df, is.numeric, mean)
## num1 num2 chr1
## 1 10 6 a
## 2 10 6 b
## 3 10 6 c
map(keep(df, is.numeric), mean)
## $num1
## [1] 10
##
## $num2
## [1] 6
9.7 Base functionals
이 chapter를 끝내기 전에, 중요한 base functionals의 survey를 소개해겠다.
To finish up the chapter, here I provide a survey of important base functionals.
얘네들은 map, reduce, predicate families가 아니고, purrr에 동등한 그런 것equivalent도 없다.
하지만 이게 중요하지 않다는 건 아니고, 수학적 혹은 통계학적 색채flavour가 있다.
그래서 data analysis에서는 덜 중요하다.
9.7.1 Matrices and arrays
map()과 그 friends는, 1차원 벡터를 다루는데 특화specialized되어 있다.
base::apply()는 2차원 혹은 다차원 벡터들(matrices, arrays)을 다루는데 특화specialized되어 있다.
apply()는 matrix나 array를, 각 row나 칼럼을 하나의 값으로 요약하는 operation이라고 생각할 수 있다.
이 것은 4개의 arguments를 가지고 있다.
1. x, 요약할 matrix나 array
2. MARGIN, integer vector, 어떤 dimension으로 요약할 건지, 1이면 rows로, 2이면 columns로.
3. FUN, 요약할 함수summary function
4. ..., FUN에 전달할 다른 arguments
apply()의 전형적인 예는 다음과 같다.
a2d <- matrix(1:20, nrow = 5)
a2d
## [,1] [,2] [,3] [,4]
## [1,] 1 6 11 16
## [2,] 2 7 12 17
## [3,] 3 8 13 18
## [4,] 4 9 14 19
## [5,] 5 10 15 20
apply(a2d, 1, mean)
## [1] 8.5 9.5 10.5 11.5 12.5
apply(a2d, 2, mean)
## [1] 3 8 13 18
multiple dimensions를 MARGIN으로 특정specify할 수 있다. 다차원 array를 다룰 때 유용하다.
a3d <- array(1:24, c(2, 3, 4))
apply(a3d, 1, mean)
## [1] 12 13
apply(a3d, c(1, 2), mean)
## [,1] [,2] [,3]
## [1,] 10 12 14
## [2,] 11 13 15
apply()를 이용하는데 있어 2개의 경고사항caveat이 있다.(3개인데?)
/1. base::sapply()와 같이, output type을 control할 수는 없다.
자동적으로 list, matrix, vector로 단순화된다.
하지만, 보통 apply()를 numeric arrays, numeric summary function이랑 쓰기 때문에,
sapply()보다는 이런 문제를 닥치게encounter 될 일은 없다.
/2. apply()는 idempotent하지 않다. (idempotent - 몇 번의 계산을 해도 같은 결과가 나오는 것)
identity operator를 summary function으로 써보면 알 수 있다.
output이 input과 항상 같지 않다.
a1 <- apply(a2d, 1, identity)
identical(a2d, a1)
## [1] FALSE
a2 <- apply(a2d, 2, identity)
identical(a2d, a2)
## [1] TRUE
/3. 절대 apply()를 데이터 프레임에다가 쓰지마라.
항상 matrix로 강제 변환하기 때문에, 데이터 프레임에 숫자가 아닌 다른 것들이 있으면, 원치 않은 결과가 나오게 된다.
df <- data.frame(x = 1:3, y = c("a", "b", "c"))
apply(df, 2, mean)
## Warning in mean.default(newX[, i], ...): argument is not numeric or
## logical: returning NA
## Warning in mean.default(newX[, i], ...): argument is not numeric or
## logical: returning NA
## x y
## NA NA
9.7.2 Mathematical concerns
수학에서 functionals는 매우 흔하다.
limit, maximum, roots(f(x) = 0이 되는 값들, solutions), definite integral 모두 functionals다.
함수가 주어지고, single number나 vector of numbers를 return한다.
처음 딱 보기에는, 루프를 제거하는 주제와는 맞지 않다고 생각할 수 있는데,
더 깊이 들어가보면 iteration을 수반involve한 알고리즘으로 implemented되었다.
base R은 유용한 셋을 제공provide한다.
1. integrate()는 f()로 정의된 커브 아래의 area를 찾아준다.
2. uniroot()은 f()가 0이 되는 값을 찾아준다.
3. optimise()는 f()의 highest 혹은 lowest가 어디에 위치하는지, 그리고 그 값을 찾아준다.
다음의 예는 어떻게 functionals가 단순한 함수sin()에 이용될 수 있는지를 보여준다.
integrate(sin, 0, pi)
## 2 with absolute error < 2.2e-14
sin(0)에서 sin(pi)까지의 넓이.
-의 개념도 있는듯. integrate(sin, 0, 2 * pi)하면 0이 나옴.
나머지도 직접 해보자.
str(uniroot(sin, pi * c(1 / 2, 3 / 2)))
## List of 5
## $ root : num 3.14
## $ f.root : num 1.22e-16
## $ iter : int 2
## $ init.it : int NA
## $ estim.prec: num 6.1e-05
str(optimise(sin, c(0, 2 * pi)))
## List of 2
## $ minimum : num 4.71
## $ objective: num -1
str(optimise(sin, c(0, pi), maximum = TRUE))
## List of 2
## $ maximum : num 1.57
## $ objective: num 1